Everything can be expressed in numbers, said Alan Turing and Kurt Gödel when they were thinking up methods to come to mathematical statements and proofs – about mathematical statements and proofs. Turing sought a systematic approach to tackle Hilbert’s Entscheidungsproblem, while Gödel used his eponymous numbering system to prove his own incompleteness theorems. Which happened to constitute a negative proof to the same Eintscheidungsproblem. You can go back one post if you are interested in the particulars.
In that previous post, I have already attributed the ascent of the universal automata – computers – to this approach. Now I will show how this same approach enabled the mathematical treatment of language, giving birth to the processing of human languages on computers.
In fact, there were two techniques that gave birth to natural language processing. One of them follows from the basic approach of Turing and Gödel. The other is related to the actual mathematical theories that were tackled using these methods.
First: Everything can be a number
Letters, punctuation symbols, spaces, breaks, logograms, you name it. Anything that belongs to written (and later, spoken) language. This is how computers learned to write: to store and display texts in human language, without understanding them of course. The principle is the same as that of the Baudot code, used from 1901 in telegraph machines (teleprinters). We assign a number to every letter and other symbol, together known as characters.
Even though the letters-as-numbers approach had been there for a long time, the first computers communicated in numbers only. Lights, switches, punched tapes, to be exact. People then created machines that punched paper tapes or cards as we typed text: the puncher machine was attached to a teletype machine. The paper tapes or cards could be fed into a tape or a card reader attached to a computer: that’s how programs and data – including text – made their way into computers back then (I’m talking about the 1960s and earlier).
Conversely, when the computer produced output (as a result of running a program), it controlled a tape or a card puncher to make it visible. The paper tape or the batch of cards was then fed into another reader, connected to a teleprinter, and if the output was text, it was printed on paper.
The teletype-reader-puncher-teleprinter routine was all offline: the paper tapes or cards had to be manually carried to and from the computer. Thus the users could actually see how text was turned into a sequence of numbers – and, on return, how a sequence of numbers was turned into text.
We don’t see this any longer: displays and input devices like keyboards, touchscreens, microphones became standard parts of computers. When we hit a key, when we tap a button on the touchscreen, when we use a digital pen to scribble words, when we speak our input – we know it’s all being turned into sequences of numbers in the background. But all that is invisible. That’s why the good old offline teletype-teleprinter setup is significant, at least for historical reasons.
Second: Everything that has an internal structure…
…can be tackled by methods of mathematics. And language does have internal structure. If we take the predominant European writing systems, we can say that written text is made up from sentences, the sentences from words, and the words from letters. In more complex texts, sentences can form paragraphs, and paragraphs are grouped into sections or chapters. Scan through this post, and spot these units.
It’s not exactly ‘language’ that has the internal structure I describe here – because written text is not equivalent to language. This will become quite important later on, but for now, let’s just say that any appearance of language – such as written text – has internal structure.
From the aspect of linguistics, this is perhaps an oversimplification – but this is the structure we can readily see when we look at written or printed text. What’s more, these structural elements – sections, paragraphs, sentences, words, and letters – are very easily identifiable because there are clear visual cues that help us separate them from each other. A new section is introduced by a heading, and often starts on a new page. A new paragraph starts in a new line after some more space above it – or the first line of the paragraph is more indented than the rest. In our languages, a sentence starts with a capital letter (there are very rare exceptions), and ends in a punctuation mark; although sometimes it’s not easy to tell if a period marks the end of a sentence or just an abbreviation. Words are preceded and followed by spaces and/or punctuation marks again; and each letter is yet another character, that is, a new, separate number in the computer’s memory. (Always provided that the text exists on a computer, of course.)
But these are just those units that we can discern without understanding the text. To tell words, sentences, paragraphs, sections apart, it’s enough to know about the numbers that represent the characters (yes, a space or the end of a paragraph are just as much characters as any letter) and the formatting. In other words, this much structure can be discovered by a computer running a rather simple program.
If we’re pessimistic, we can say that the reading capabilities of the computer stop here. Yet there is more structure to text than this: words are not just arbitrarily shoveled together (and I just hope this post is not an exception). When we learn language at school – be it our own tongue or a foreign one –, we are told about all sorts of rules where to put subjects, verbs, objects, adjectives, adverbs and whatnot to convey our meaning; how to change words to fit the place they occupy in the sentence; and so on.
Apparently, we don’t need that: the grammatical structure is there in the speech of every child learning to speak, and it gets more and more complex as the child gets older. At school, it seems we’re just told about the names of such components, so that we can execute learned talk about them.
Perhaps inspired by the successes of mathematics, chemistry, physics, and biology, the early 20th century saw the beginning of the structuralist movement in linguistics. With some simplification, we can say that there have been three different approaches to linguistics – the study of language – over time. One was concerned with how certain languages should be spoken: prescriptive linguistics, rooted in rhetorics, was instrumental in reviving many languages in the 19th and the 20th centuries, with Hungarian, Norwegian, Turkish, or Hebrew as examples. This approach went on to meld with social science, to become a field of sociolinguistics today known as language policy. On a side note, language policy, both in its early stages and in its modern form, has done a great deal to promote translation, raising the profile of the profession this blog is about.
The historic, or to put it in a Popperian term, historicist approach, deals with the relation of languages, and strives to put them in connection with the history of the nations that speak them. This type of study was typical to the Romantic era, when most national identities, forming most modern European states, were born and amplified.
On the other hand, structuralists have always been concerned with what language is like. To put it bluntly, they aspire to study language as a natural phenomenon (which, from many aspects, it is), and apply similar methods as those of physics or chemistry. What’s more, they think that language is first and foremost the product of the mind, so one must connect the study of language with psychology.
From the various structuralist trends (Bloomfield’s behaviorist school in the US, or the lesser-known Prague School, to name just two), generative grammar and generative linguistics were born. Started by Noam Chomsky, this is the structuralist approach in its cleanest form, stripping down the study of language to pure mathematics, severing language from the other cognitive functions of the human mind.
Generative grammar considers a specific language as a – mathematically infinite – set of utterances, or sentences. Each sentence is built up using a set of rules, specific to the language. When someone is about to speak a sentence, they start from a single root symbol, and then they break it down to smaller units – the smaller units are then broken down into even smaller units, until the speaker reaches the symbols they will actually speak.
The definitive work on this theory is Chomsky’s Syntactic Structures, although the original generative theory spawned a number of improvements and various derivative phrase structure grammars (and related linguistic theories).
Let me give you an (again, oversimplified) example. Take the sentence ‘I am writing a blog post’.
I may be putting together this sentence from a subject and a predicate. In the mathematical formalism called rewrite rules, it looks like this:
S → SUBJ PRED
The subject is myself, which is expressed with a personal pronoun ‘I’:
SUBJ → PRON
The predicate is more interesting because it’s put together from a verbal phrase and an object, expressed with a noun phrase:
PRED → VP NP
The verbal phrase is now a compound form, consisting of an auxiliary verb and the gerund form of a main verb:
VP → AUX V GER
… and the subject – the noun phrase after the verbal phrase – is a compound of an indefinite article (or determiner) and two nouns (which can be looked at as an unmarked possessive structure such as ‘post of blog’ – such structures are more widely used in Romance languages):
NP → DET N N
Down to the word level, our sentence looks like this:
S → PRON AUX V GER DET N N
What I actually say is this:
I (PRON) am (AUX) writ (V) ing (GER) a (DET) blog (N) post (N).
Generative linguistics calls the thing I actually say the surface form, or surface structure of my utterance. (S means sentence, but I like ‘utterance’ better because we do not always speak in fully formed sentences.) The path of applying all those (rewrite) rules outlined above is called the deep structure of my utterance.
The deep structure can also be drawn up as a tree:
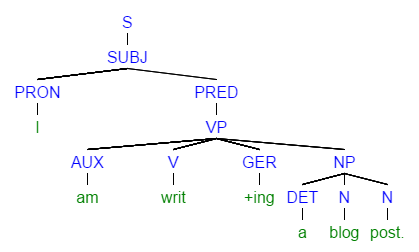
This becomes even more exciting when you start saying things like ‘clear, bright, blue sky’ with all the adjectives preceding the noun. Of course, you can find a rewrite rule that handles it nicely:
NP → ADJ ADJ ADJ N
But what if you don’t know how many adjectives can come before the noun? You can assume that a speaker can say any number of them. So, what if you write all these rewrite rules for noun phrases?
NP → N
NP → ADJ NP
Look at the second rule: it says that you can say any NP after an adjective. Now an NP can be a single noun – or another construct that starts with an adjective, and is followed by another NP.
This vicious circle is called recursion, which, if you wish to observe it in nature, usually appears as the same structure within a larger structure, repeating endlessly as we scale down.
Remember: this is a theory of human language. It assumes that anything we say on the surface corresponds to something deeper in our minds, consisting of a lot of unspoken units. Generative theory also assumes that everyone has an innate ability to build up structures like the ones above, and to use them to say things that adhere to the rules of a language, and are intelligible in that language.
Chomsky calls this innate ability ‘competence’, and the things we actually say are called the ‘performance’. Competence encompasses anything that can be said, while performance consists of things that have been said.
For now, the point is that Chomsky, his predecessors, and his followers managed to express human language in mathematical symbols. And from Gödel and Turing, we know that mathematical symbols can be represented in numbers – and numbers can be processed by different kinds of automata, that is, theoretical machines. Specialized theoretical machines are implemented in the form of computer programs, where the computer is the universal automaton (in the physical, mostly electronic, form) that can operate the programs.
To facilitate computational processing, Chomsky distinguished between four different classes of grammars, together known as the Chomsky hierarchy, judging by their complexity. Grammars in each class can be implemented using automata of different complexity. ‘Implementing a grammar’ means that you create a machine – a computer program – that can generate sentences from that grammar, and, conversely, one that can analyze, parse sentences to see if they adhere to the rules of that grammar, and if they do, discover their deep structure like the one above.
Today, only the two easiest grammar classes can be put to practical use: programmers can construct automata of viable performance for these. The least complex grammar class – the one that imposes the strictest restrictions on what can be in a rule – is regular grammars that can be processed with finite-state machines. Programmers know this class from regular expressions, which are equivalent to regular grammars and the programs that work them actually implement finite-state machines.
Today, the mathematical theory of languages is very efficiently used with artificial languages, that is, programming languages on computers, and telecommunication protocols. However, linguists aimed to use them first and foremost for human languages: more specifically, for automated translation. Most rule-based machine translation programs are based on some late descendant of the theory outlined here.
The results of applying mathematical theory to human language were formidable, but never as accurate or efficient as with artificial languages. In the middle of the 20th century, generative-minded linguists seriously believed that they cracked the cognitive mechanism behind human language. Such rationalism was the spirit of those times. The brightest witnesses to this are probably Chomsky’s own two writings (beside Syntactic Structures), Language and Mind, and Cartesian Linguistics.
In the next post, I plan to explain why many think Chomsky and his peers were wrong in their assumptions about the human mind – and how mankind, realizing that pure mathematical langage theory doesn’t work, turned to different resources, and became somewhat cynical about the computational treatment of human language.

One thought on “Language in Numbers”